Domain Entity pattern
The Domain Entities are a fundamental building block of Domain-Driven Design1, and they're used to model concepts of your Ubiquitous Language in code.
Entities are Domain concepts that have a unique identity in the problem domain
Entities represent domain objects and are primarily defined by their identity, continuity, and persistence over time, and not only by the attributes that comprise them. As Eric Evans says, “an object primarily defined by its identity is called an Entity.” Entities are very important in the domain model, since they are the base for a model. Therefore, we should identify and design them carefully.
Natural keys from the problem domain, application generated, and datastore generated are all techniques for creating entity IDs.
An entity’s identity can cross multiple services or Bounded Contexts
The same identity (though not the same entity) can be modeled across multiple Bounded Contexts or services. However, that does not imply that the same entity, with the same attributes and logic would be implemented in multiple Bounded Contexts. Instead, entities in each Bounded Context limit their attributes and behaviors to those required in that Bounded Context’s domain.
For example, a buyer entity might have most of a person’s attributes that are defined in the user entity in the profile or identity service, including the identity. But the buyer entity in the ordering service might have fewer attributes, because only certain buyer data is related to the order process. The context of each service or Bounded Context impacts its domain model.
Domain entities must implement behavior in addition to implementing data attributes
A domain entity in DDD must implement the domain logic or behavior related to the entity data (the object accessed in memory). For example, as part of an order entity class we must have business logic and operations implemented as methods for tasks such as adding an order item, data validation, and total calculation. The entity’s methods take care of the invariants and rules of the entity instead of having those rules spread across the application layer.
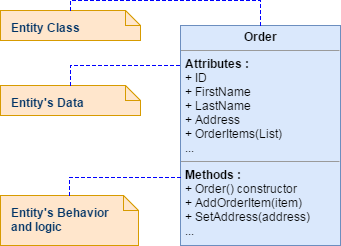
Sometimes we can have entities that do not implement any logic as part of the entity class. This can happen in child entities within an aggregate if the child entity does not have any special logic because most of the logic is defined in the aggregate root. If you have a complex microservice that has a lot of logic implemented in the service classes instead of in the domain entities, you could be falling into the anemic domain model, explained in the following section.
Entities are domain object that have a life cycle
There are three main objects that can control the life-cycle of a domain object:
- Aggregates: Hold several objects in a root object and can control their creation, manipulation, query and deletion.
- Factories: Create new objects with a set of data.
- Repositories: Recreate persisted objects from queried data, possibly delegating the reconstruction of the actual object instance to a factory.
Rich domain model versus anemic domain model
In his post "Anemic Domain Model"2, Martin Fowler describes it this way:
The basic symptom of an anemic domain model is that at first blush it looks like the real thing. There are objects, many named after the nouns in the domain space, and these objects are connected with the rich relationships and structure that true domain models have. The catch comes when you look at the behavior, and you realize that there is hardly any behavior on these objects, making them little more than bags of getters and setters.
Of course, when you use an anemic domain model, those data models will be used from a set of service objects (traditionally named the business layer) which capture all the domain or business logic. The business layer sits on top of the data model and uses the data model just as data.
The anemic domain model is just a procedural style design. Anemic entity objects are not real objects because they lack behavior (methods). They only hold data properties and thus it is not object-oriented design. By putting all the behavior out into service objects (the business layer) you essentially end up with spaghetti code3 or transaction scripts4, and therefore you lose the advantages that a domain model provides.
Regardless, if your service or Bounded Context is very simple (a CRUD service), the anemic domain model in the form of entity objects with just data properties might be good enough, and it might not be worth implementing more complex DDD patterns. In that case, it will be simply a persistence model, because you have intentionally created an entity with only data for CRUD purposes.
That is why microservices architectures are perfect for a multi-architectural approach depending on each Bounded Context. Some people say that the anemic domain model is an anti-pattern. It really depends on what you are implementing. If the service you are creating is simple enough (for example, a CRUD service), following the anemic domain model it is not an anti-pattern. However, if you need to tackle the complexity of a microservice’s domain that has a lot of ever-changing business rules, the anemic domain model might be an anti-pattern for that service or Bounded Context. In that case, designing it as a rich model with entities containing data plus behavior as well as implementing additional DDD patterns (aggregates, value objects, etc.) might have huge benefits for the long-term success of such a service.
1. “Domain-driven Design”, This content ↩
2. “Anemic Domain Model”, Martin Fowler, https://martinfowler.com/bliki/AnemicDomainModel.html ↩
3. “spaghetti code”, Wikipedia, https://en.wikipedia.org/wiki/Spaghetti_code ↩
4. “Transaction Script”, Martin Fowler, https://martinfowler.com/eaaCatalog/transactionScript.html ↩